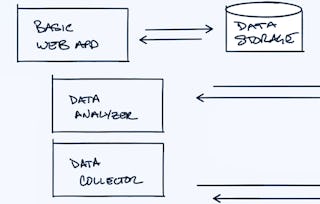
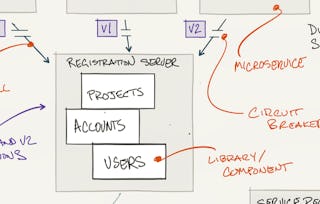
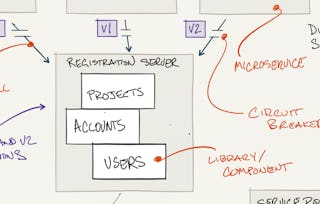
The course is intended for individuals looking to understand the architecture patterns necessary to take large software systems that make use of big data to production.
You will transform big data prototypes into high quality tested production software. After measuring the performance characteristics of distributed systems, you will identify trouble areas and implement scalable solutions to improve performance. Upon completion of the course you will know how to scale production data stores to perform under load, designing load tests to ensure applications meet performance requirements. This course can be taken for academic credit as part of CU Boulder’s MS in Data Science or MS in Computer Science degrees offered on the Coursera platform. These fully accredited graduate degrees offer targeted courses, short 8-week sessions, and pay-as-you-go tuition. Admission is based on performance in three preliminary courses, not academic history. CU degrees on Coursera are ideal for recent graduates or working professionals. Learn more: MS in Data Science: https://www.coursera.org/degrees/master-of-science-data-science-boulder MS in Computer Science: https://coursera.org/degrees/ms-computer-science-boulder